

Google Shopping Feed-Tests gehören zu den wirkungsvollsten Aktivitäten, die ein Performance-Team durchführen kann – doch die meisten Marken behandeln sie nach dem Motto „Änderung pushen, eine Woche Dashboard beobachten und nach Bauchgefühl den Gewinner auswählen." Das ist kein Test, das ist Rauschen. Shopify-Plus-Teams mit Shopping-Budgets von 50.000+ $/Monat sind zu einer 3-Kohorten-Custom-Label-Methode übergegangen, die Feed-Variablen mit ausreichender statistischer Power isoliert, um 8–15% CTR-Steigerungen pro Quartal auf spezifische Titel- und Attribut-Änderungen zurückzuführen – bevor der gesamte Katalog angepasst wird.
Warum Standard-PMax-„Experimente" Feed-Level-Variablen verfehlen
Performance-Max-Experimente auf Kampagnenebene – der Tab „Experiment" in Google Ads – teilen das Budget zwischen zwei Kampagnenkonfigurationen auf. Sie können jedoch eine Feed-Änderung nicht als unabhängige Variable isolieren. Wenn du einen Produkttitel katalogweit veränderst und danach ein PMax-Experiment startest, hast du bereits beide Testgruppen kontaminiert: jede Impression bedient nun den neuen Titel, und die Kontrollgruppe existiert nicht mehr.
Googles eigene Merchant-Center-Dokumentation zu Experimenten bestätigt diese Lücke implizit: Die unterstützten Experimenttypen decken Gebote, Creative Assets und URL-Erweiterungen ab – nicht Feed-Attribute. Das bedeutet, dass eine Titel-Neugestaltung, eine Marken-Präfix-Änderung oder das Verschieben von Material-Attributen in Position 2 eines Titelstrings nicht nativ in der Ads-Oberfläche getestet werden können.
Die Folge ist echtes Geld, das auf dem Tisch liegenbleibt. In einem Katalog mit 2.400 SKUs führt eine auf Bauchgefühl basierende Titel-Format-Änderung, die eine 6%-CTR-Verschlechterung zur Folge hat, zu einer Beeinträchtigung jeder Shopping-Impression in diesem Katalog – ohne Möglichkeit, den Rückgang zurückzuverfolgen. Es kann 3–4 Wochen dauern, bis du es merkst – lange genug, dass ein Quartalsbericht ein falsches Bild zeichnet. Vor jeder katalogweiten Änderung lohnt sich ein Audit deines Feeds nach Attributlücken, die von Anfang an Störvariablen einführen könnten.
Die drei Variablen, die PMax-Experimente tatsächlich steuern
PMax-Experimente handhaben: (1) Creative-Asset-Gruppen, (2) Smart-Bidding-Strategievarianten (tROAS vs. Konvertierungswert maximieren) und (3) URL-Erweiterungs-Toggles. Feed-Level-Signale – Titel, Beschreibungen, Produkttypen, GTINs, Custom Labels – liegen vor der Auktion. Sie bestimmen, in welche Anfragen deine Anzeigen eintreten dürfen, nicht nur, wie du in sie bietest. Tests auf der falschen Ebene zu führen beantwortet die falsche Frage.
Die 3-Kohorten-Split-Methode: Segmentierung nach Custom Label
Die 3-Kohorten-Custom-Label-Methode ist der zuverlässigste Ansatz zur Isolierung von Feed-Variablen in einer Live-Shopping-Umgebung. Sie nutzt drei Kohorten, definiert durch custom_label_0 (oder whichever Label-Slot in deinem Feed frei ist). Beschrifte deinen SKU-Pool als control, variant_a und holdout, bevor du Titel oder Attribute veränderst. Die Holdout-Gruppe – typischerweise 20% der SKUs – bleibt unverändert und läuft durch dieselben Kampagnen ohne Änderung, was dir eine Baseline gibt, die externe Saisonverschiebungen berücksichtigt.
Hier ist die Kohorten-Zuordnungsformel, die wir über mehrere Shopify-Plus-Konten hinweg validiert haben:
| Kohort | Label-Wert | SKU % | Zweck |
|---|---|---|---|
| Kontrolle | test_ctrl | 40% | Original-Feed-Attribute, Business as usual |
| Variante A | test_var_a | 40% | Geänderte Titel / getestete Attribute |
| Holdout | test_hold | 20% | Unverändert; Saisonalität / Marktkorrektur |
Die Zuweisung von Custom Labels in großem Maßstab erfordert einen Zusatz-Feed statt der Bearbeitung deines Haupt-Feeds. Erstelle in deinem Merchant-Center-Konto einen Zusatz-Feed, der nur auf id + custom_label_0 abgebildet ist. Dies hält deinen Haupt-Feed sauber und ermöglicht es dir, Label-Werte programmatisch über die Content API zu wechseln, ohne einen kompletten Feed neu hochzuladen.
Sobald Labels zugewiesen sind, segmentiere deine Shopping- oder PMax-Kampagnen nach Label mit Kampagnen-Level-Produktfiltern. Kontrolle und Variante A erhalten identische Budgets, identische Gebots-Strategien und identische Asset-Gruppen. Die einzige Variable, die sich unterscheidet, ist das, was im Feed steht. Wenn du mehr als eine Shopping-Kampagne hast, musst du Kreuzkontamination handhaben – mehr dazu in einem späteren Abschnitt.
Für Teams, die die KI-Umschreib-Engine von MagicFeed Pro nutzen, kann der KI-Feed-Optimizer-Workflow Varianten-Titel für deine Test-Kohort in Masse generieren, während Kontroll-Titel unverändert bleiben – ein Schritt, der früher einen vollen Tag Spreadsheet-Arbeit brauchte.
Festlegung statistischer Signifikanz-Schwellen (Sample-Size-Mathematik)
Einen Test 14 Tage lang zu fahren und einen Gewinner basierend auf einem 3%-CTR-Unterschied zu erklären, ist wie Marken sich selbst täuschen. Bevor du einen Feed-Test startest, berechne die minimal erkennbare Effektgröße (MDE) und erforderliche Sample Size anhand deines Baseline-Click-Volumens. Dieser Schritt richtig zu machen unterscheidet ein verteidigbares Ergebnis von einem Bauchgefühl-Aufruf, der sich in Daten kleidet.
Die Standard-Formel, abgeleitet von Evan Millers Sample-Size-Rechner-Methodologie, zielt auf:
- Statistische Power: 80% (β = 0,20)
- Signifikanzniveau: 95% (α = 0,05, zweiseitig)
- MDE: der kleinste CTR-Anstieg, der handlungsfähig ist (typisch 5–8% relativ für Feed-Tests)
Für eine Baseline-CTR von 1,2% und eine MDE von 6% relativ (bedeutet, du möchtest einen Anstieg auf 1,27% oder höher erkennen), brauchst du ungefähr 18.400 Impressionen pro Kohort. Bei einem typischen Shopping-Kampagnen-Impressions-Tempo von 1.500 Impressionen/Tag pro Kohort bei diesem Budget-Level sind das ein 12-Tage-Minimum – nicht 7 und nicht die „Lass uns Freitagnachmittag kurz schauen"-Gewohnheit, in die die meisten Teams verfallen.
Beende einen Feed-Test niemals am Wochenende oder verkürze ihn während einer Aktionsperiode. Feiertagswochenenden, Flash Sales und sogar Konkurrenz-Promotions verschieben CTR-Baselines um 15–30%, invalidieren den Vergleich. Wähle ein 14-Tage-Fenster, das zwei volle Geschäftswochen umfasst, ohne geplante Promotions auf beiden Seiten.
Für Teams mit kleineren Katalogen (unter 500 SKUs pro Kohort) oder niedrig-Traffic-Kategorien liefert die Mathematik oft erforderliche Fenster von 21–28 Tagen. Das ist unbequem, aber richtig. Einen Test am Tag 10 mit p = 0,08 zu beenden ist nicht „Tendenzen zeigen Signifikanz" – es ist ein unter-gepowerter Test mit einer Münzwurf-Schlussfolgerung.
Die primäre Metrik für Feed-Tests sollte CTR auf Impressions-Ebene (Klicks ÷ Impressionen) sein, nicht Konvertierungsrate. Konvertierungsrate führt stromabwärts gelegene Variablen ein – Landing-Page-Erlebnis, Preiskonkurrenzfähigkeit, Verfügbarkeit – die außerhalb des Feed-Kontrolle liegen. Isoliere den Job des Feeds: den Klick holen.
Case Study: Titel-Format-Test über 2.400 SKUs (14-Tage-Fenster)
Eine Shopify-Plus-Modemarke mit ungefähr 65.000 $/Monat Google Shopping Budget führte einen Titel-Format-Test in Q1 2026 mit der oben beschriebenen 3-Kohorten-Methode durch. Die Test-Variable war Titel-Struktur: Kontrolle nutzte den Standard-Shopify-Produkttitel (Marke + Produktname + Farbe), während Variante A zu Marke + Geschlecht + Produktkategorie + Schlüsselattribut + Farbe umstrukturiert – ein Format, das Such-Intent-Signale an den Anfang stellt. Diese Art von strukturierter Titel-Umgestaltung gehört zu den wirkungsvollsten Änderungen, die in der Produkttitel-Optimierung für Google Shopping dokumentiert sind.
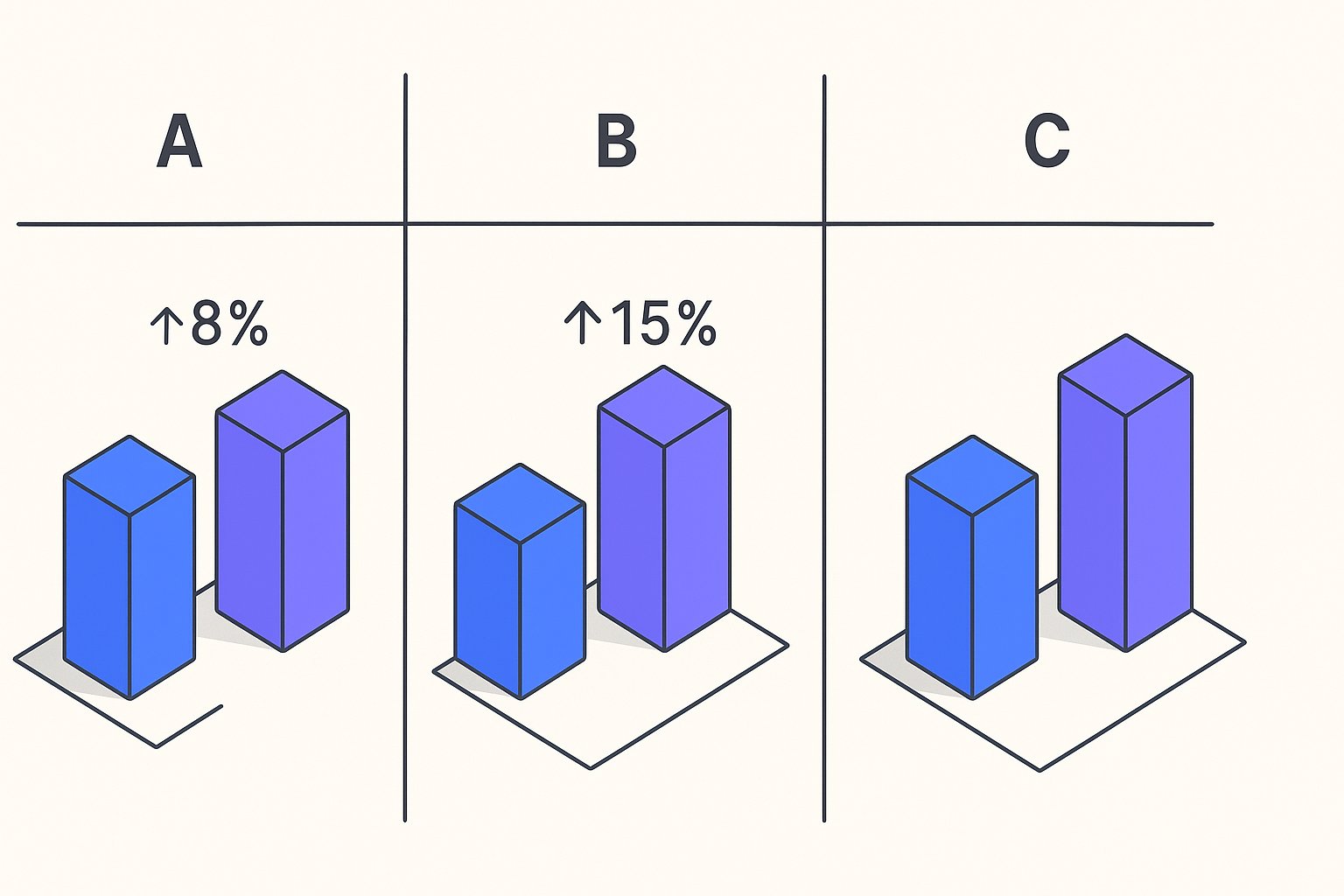
Ergebnisse nach 14 Tagen über 2.400 SKUs (800 pro Kohort):
| Metrik | Kontrolle | Variante A | Steigerung |
|---|---|---|---|
| Impressionen | 312.400 | 308.900 | — |
| Klicks | 3.748 | 4.271 | +13,9% |
| CTR | 1,20% | 1,38% | +15,0% |
| Konv.-Rate | 2,14% | 2,19% | +2,3% (ns) |
| p-value | — | — | 0,003 |
Die CTR-Steigerung von 15% überschritt die 95%-Konfidenz-Schwelle komfortabel (p = 0,003). Die Konvertierungsrate-Verbesserung war nicht statistisch signifikant – was erwartet wurde, da der Test nur den Feed änderte, nicht die Landing Page. Das Team rollte Varianten-A-Titel auf die restlichen 1.600 SKUs aus und sah die Steigerung in den folgenden 30 Tagen innerhalb von 2 Prozentpunkten halten.
Veröffentliche dein Test-Design – Kohortengröße, MDE, Dauer – bevor du das Experiment startest. Teams, die ihre Erfolgskriterien vorab registrieren, haben eine deutlich geringere Wahrscheinlichkeit, sich auf „p-Hacking" einzulassen (den Test zu stoppen, wenn die Zahl gut aussieht). Ein geteiltes Google Sheet mit der Hypothese, Metriken und Schwelle, die vor Tag 1 gesperrt sind, dauert unter 20 Minuten und amortisiert sich jedes Mal, wenn das Ergebnis mehrdeutig ist.
Du kannst weitere Titel-Format-Auswirkungsbeispiele über verschiedene Verticals hinweg in den MagicFeed Pro Optimierungs-Case-Studies erkunden, einschließlich einer Möbelmarke, die Attribut-Reihenfolge über 5.400 SKUs testete und einen 19%-CTR-Rückgang wiederherstellte, der durch eine frühere nicht-getestete Feed-Überholung verursacht wurde.
Vermeidung von Kreuzkontamination in gemeinsamen Shopping-Kampagnen
Kreuzkontamination ist der häufigste Grund, warum Feed-Tests stillschweigend fehlschlagen. Sie tritt auf, wenn Kontroll- und Varianten-SKUs in der gleichen Ad Group konkurrieren oder wenn Googles Smart-Bidding-Algorithmus das Budget zu der Kohort umverteilt, die während des Tests besser zu performen scheint. Das Eliminieren dieser Vektoren vor dem Launch ist nicht verhandelbar.
Drei spezifische Kontaminationsvektoren, die vor dem Launch eliminiert werden müssen:
1. Gemeinsame Ad Groups. Wenn beide Kohorten in der gleichen Ad Group leben, wird Google die höher-CTR-Kohort automatisch priorisieren, während der Test fortschreitet und die Impression-Share der Variante auf Kosten der Kontrolle aufblahen. Der Custom-Label-Filter auf Kampagnen-Ebene (nicht Ad-Group-Ebene) ist die strukturelle Lösung.
2. Smart-Bidding-Learning-Bleed. tROAS und Maximize-Conversion-Value-Strategien teilen einen Performance-Signal-Pool über Kampagnen hinweg im gleichen Konto. Eine Gebotsstrategieänderung, die durch Varianten-A-Performance ausgelöst wird, kann in 48–72 Stunden in Kontrollkampagnen-Gebots-Verhalten durchsickern. Nutze separate, unabhängige Gebots-Strategien für jede Kohort – auch wenn das identische tROAS-Ziele bedeutet, die über zwei Kampagnen dupliziert werden.
3. Remarketing-List-Überlappung. Wenn deine Shopping-Kampagnen Audience-Signale nutzen, die Kohorten überlappen (häufig bei breiten First-Party-Listen), können Nutzer, die Kontroll-Anzeigen sahen, von Varianten-A-Impressionen retargetet werden und Exposures-Daten mischen. Segmentiere deine RLSA-Audiences nach Kaufhäufigkeit und schließe die Top-Häufigkeits-Segmente von beiden Test-Kampagnen während des Run-Fensters aus.
Für Konten mit komplexen Multi-Kampagnen-Strukturen deckt Shopifys Dokumentation zum Google Shopping Channel ab, wie Zusatz-Feed-Architekturen mit Kampagnen-Produktfiltern interagieren – nützlicher Hintergrund bei der Gestaltung von Label-Hierarchien über 10+ aktive Kampagnen hinweg.
Tooling: Google-Sheets-Vorlage + Merchant-Center-API-Workflow
Ein verlässlicher Feed-Test wird durch seine operative Grundlage bestimmt oder sabotiert. Manuelle Label-Zuweisung über Tausende SKUs ist fehleranfällig; gleiches gilt für die manuelle tägliche Signifikanz-Prüfung. Hier ist der minimale Tooling-Stack, der ohne Data-Engineering-Team skaliert.
Kohorten-Zuweisung (Google Sheets + IMPORTDATA): Verwalte eine Master-SKU-Liste mit einer cohort-Spalte. Nutze =RANDBETWEEN(1,100) bei der initialen Zuweisung mit einem Cutoff (1–40 = Kontrolle, 41–80 = Variante, 81–100 = Holdout) – kritisch: Paste Werte sofort danach, um die Zufallszuweisung zu frieren. Kohorten, die bei jedem Sheet-Öffnen regeneriert werden, produzieren verschiedene Zuweisungen jeden Tag und verderben den Test.
Zusatz-Feed (Merchant Center Content API): Nutze die Merchant Center Content API, um custom_label_0-Updates von deiner Sheets-Zuweisung über ein leichtes Apps Script oder Python-Skript zu pushen. Dies vermeidet die 24-Stunden-Verarbeitungsverzögerung, die mit manuellen Zusatz-Feed-Uploads verbunden ist, und gibt dir nahezu Echtzeit-Label-Kontrolle – kritisch, wenn du eine Kohort wegen einer Anomalie pausieren musst.
Signifikanz-Tracking (Apps Script + evanmiller.org-Formel): Repliziere die Zwei-Proportionen-z-Test-Formel direkt in Sheets. Pull tägliche Impressions- und Klick-Daten von der Google Ads API in eine laufende Tabelle. Die z-Test-Formel für zwei Proportionen:
z = (p1 - p2) / sqrt(p_pool * (1 - p_pool) * (1/n1 + 1/n2))
wo p_pool = (x1 + x2) / (n1 + n2). Markiere die p-value-Spalte rot, wenn p > 0,05 und grün, wenn p ≤ 0,05 – eine Zwei-Sekunden-Sicht-Prüfung ersetzt eine Stunde manuelle Analyse.
Bevor du einen Test fährst, führe deinen Feed durch das MagicFeed Pro Feed-Audit-Tool, um Attributlücken zu identifizieren, die Störvariablen einführen könnten – ein fehlendes size_type auf 30% der Varianten-SKUs würde beispielsweise diese SKUs für größen-gefilterte Anfragen unterdrücken und Varianten-A-CTR falsch deprimieren.
Der komplette Workflow – Sheets-Vorlage, Apps Script für API-Sync und Signifikanz-Tracker – kann in etwa 3 Stunden für ein Team mit bereits konfiguriertem API-Zugriff eingerichtet werden. Das ist eine einmalige Investition, die jeden nachfolgenden Test schneller und verteidigbarer für Stakeholder macht, die die Mathematik sehen wollen, bevor sie eine katalogweite Rollout genehmigen.
Verwandte Artikel

KI-Suche formt Google Shopping neu: Feed für SGE 2026
6 Feed-Attribute bestimmen, welche Produkte in KI-Überblick-Karussellen erscheinen. Optimieren Sie Ihren Shopping-Feed jetzt für die KI-Ära.
Regelbasierte Feed-Tools: Wo die Grenzen liegen
Channable-Alternative für Google Shopping: Regelbasierte Feed-Tools scheitern bei Skalierung auf 5 vorhersehbare Wege. Echte Kosten und wie AI-Umschreibung in unter einem Tag hilft.
Bundles & Multipacks für Google Shopping mit AI optimieren
Google Shopping Bundle-Optimierung schlägt fehl, wenn AI Mengenangaben entfernt. Beheben Sie Multipack-Attribute und stellen Sie fehlende Impressionen in unter einer Stunde wieder her.